
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 하이드잭
- 블로그
- 출사
- GUI개발
- EOS 100D
- DALL-E
- 제이웨딩
- Jekyll
- ChatGPT
- HS겨울눈꽃체2.0
- 캘리그래피
- 카메라로우
- 국립세종수목원
- Hydejack
- dask
- 예산시장
- Github Pages
- 공주산성 #청설모 #출사 #하이킹 #날씨 더움
- Python
- PyQt6
- 날먹
- AI
- 토끼네활자공장
- Nikon Z5
- pandas
- Photoshop
- NIKKOR Z 40mm f/2
- Prompt Engineering
- Jekyll Theme
- Canon
- Today
- Total
찍찍의 기록
[파이썬] 대용량 Dataframe 처리를 위한 DASK Library 기본 활용법 본문
최근들어 대용량 Dataframe을 읽기 위해 Pandas 외 다른 대용량 Dataframe처리가 가능한 Library를 필요로 하게 되었습니다.
AI 업무를 하면서 별 생각없이 Pandas를 자주 사용하는 편입니다만, 대용량 데이터프레임을 다룰 때 아래와 같은 에러를 가끔 마주하게 됩니다. (Unable to allocate ~~ GiB for an array with shape ~~)

Pandas는 Single-Thread로 작동하기 때문에 대용량 데이터를 처리하는 데 한계가 있습니다.
이럴 때 대체 가능한 라이브러리로 Dask, Vaex, Polars 등이 있는데, 이번 포스트는 Dask 라이브러리에 대해 다뤄보겠습니다.
Dask는 분산 처리 및 병렬 처리를 지원하여 메모리 사용을 최적화하고 대용량 데이터를 효율적으로 다룰 수 있게 해줍니다.
Pandas와 비슷한 문법 체계를 가지고 있으므로, Pandas에서 Dask로 넘어갈 때 큰 어려움은 없을 것 같습니다.
병렬 처리나 Lazy Execution으로 인해 Pandas와 달리 신경써야 하는 점이 일부 있지만, 이러한 문제는 조금 나중으로 다루고 우선 Dask의 기본 문법에 대해 간단히 알아보겠습니다.
DASK Install 및 실험용 Dataframe 생성
Dask Library를 우선 설치하고, 대용량 Dummy Dataframe을 생성해보겠습니다.
Dask를 설치하려면 다음 명령어를 사용합니다.
%pip install dask
%pip install pyarrow
%pip install jinja2Dask에서 사용하는 여러 기능들은 다른 Library를 기반으로 설치되므로, Pyarrow와 jinja2도 함께 설치가 되어야 합니다.
설치가 완료되었으니, Dask 기본 사용을 위해 Library 호출 및 Dummy CSV 파일을 생성해보겠습니다.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
# 대용량 CSV 파일 생성
num_rows = 5*(10**7) # 5천만 행
file_size_sum = 0
file_count = 10
df_path = r'C:\Users\user\Desktop'
with tqdm(range(file_count)) as pbar:
for i, prog in enumerate(pbar):
data = {
'A': np.random.randint(0, 10000, size=num_rows),
'B': np.random.rand(num_rows),
'C': np.random.choice(['string_A', 'string_B', 'string_C'], size=num_rows)
}
target_path = os.path.join(df_path, f'large_dataset_{i}.csv')
# 대용량 CSV 파일 로컬에 저장
large_df = pd.DataFrame(data)
large_df.to_csv(target_path, index=False)
# 생성된 CSV 크기 확인
file_size = os.path.getsize(target_path) / (1024 * 1024 * 1024) # GB 단위
file_size_sum = file_size_sum + file_size
pbar.set_description(f"Generated {file_size:.3f} GB CSV")
print(f"Total generated CSV size: {file_size_sum:.3f} GB with {file_count} files.")Generated 1.591 GB CSV: 100%|██████████| 10/10 [13:11<00:00, 79.19s/it]
Total generated CSV size: 15.906 GB with 10 files.파일 용량이 상당히 큰 5천만 Row짜리 Dummy CSV 파일을 10개 생성했습니다.
Pandas로 이런 큰 파일을 읽으려면 번거롭게 Chunk 단위로 읽어서 합치거나, 또는 각 Column 별 dtype을 명시적으로 지정하여 메모리 사용을 최적화해야 합니다. 기다려야 되는건 덤이구요.
DASK 기본 사용법 (읽기)
기본적인 Dataframe 읽는 방법은 read_csv(path)로, Library 이름만 다르지 Pandas와 동일합니다.
Dask와 Pandas를 함께 비교해보도록 하겠습니다.
참고로, Dask는 Wildcard (ex. file_name_*.csv) 를 지원하므로 여러개의 CSV 파일을 동시에 읽을 수 있습니다.
import dask.dataframe as dd
import time
# Pandas로 읽기
start_time = time.time()
df_list = []
for i in range(file_count):
df_list.append(pd.read_csv(os.path.join(df_path, f'large_dataset_{i}.csv')))
pandas_df = pd.concat(df_list, ignore_index=True)
pandas_time = time.time() - start_time
print(f"Pandas read time: {pandas_time:.3f} seconds")
# Dask로 읽기
start_time = time.time()
dask_df = dd.read_csv(os.path.join(df_path, 'large_dataset_0.csv'))
dask_time = time.time() - start_time
print(f"Dask read time: {dask_time:.3f} seconds")Pandas read time: 234.984 seconds
Dask read time: 0.580 seconds약 16GB의 대용량 CSV 파일 5억줄을 읽고 합치는데에 Pandas는 230초 가량이 걸렸습니다.
DASK는 1초도 걸리지 않았습니다. (애초부터 분리하지 않았으므로, concat이 필요하지 않습니다.)
실제로 다 읽은걸까요? 그렇지는 않습니다.
Dask는 데이터를 지연 실행 (Lazy Execution) 방식으로 데이터를 읽기 때문에, 실제로 데이터가 메모리에 로드되지 않았습니다.
지연 실행 (Lazy Execution)이란?
지연 실행 (Lazy Execution)은 필요할 때까지 계산을 미루는 프로그래밍 기법입니다. Dask는 데이터를 바로 메모리에 로드하지 않고, 필요한 시점에만 계산을 수행합니다. 이를 통해 메모리 사용을 최적화하고, 대용량 데이터셋을 효율적으로 처리할 수 있습니다.
그래서 실제 읽어온 데이터프레임을 읽어보면, Dask로 읽은 데이터프레임은 값이 나오지 않은 상태임을 알 수 있습니다.
# print()와 동일 (가독성만 향상)
display(pandas_df)
display(dask_df)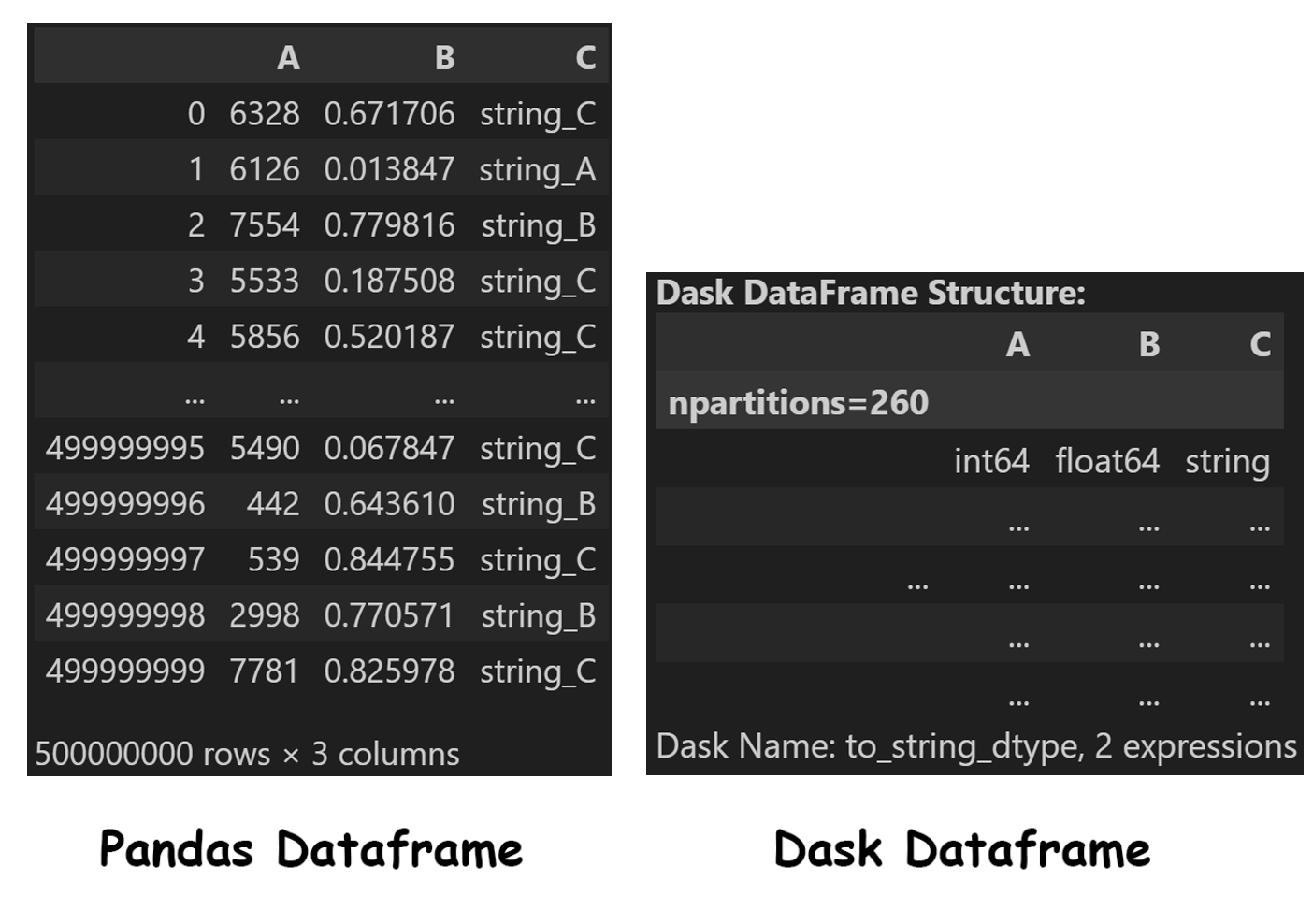
Dask는 Column의 이름 및 dtype을 담은 메타정보만을 표시하고, 실제 데이터는 필요할 때 로드됩니다.
그럼 실제 데이터프레임은 어떻게 볼까요?
DASK 기본 사용법 (메모리에 올리기)
Dask는 기본적으로 "~~를 하기로 계획을 짰습니다~" 와 같은 개념이므로, 어떤 함수를 쓰던 아직 실행이 된 것은 아닙니다. 계획을 다 짰으면 "실행" 버튼을 눌러야 비로소 스케쥴링된 작업들을 주르륵 실행하게 되는 것이죠.
`compute()` 메서드를 호출하면 Dask 데이터프레임의 실제 데이터를 메모리에 로드할 수 있습니다.
Pandas Dataframe 형태로 저장되므로, compute() 이후부턴 Pandas 문법을 그대로 사용할 수 있습니다.
어떤 전처리 작업을 하던간에, 코드 맨 마지막 부분에선 compute()를 통해 Dask Dataframe을 Pandas Dataframe으로 변환해주셔야 머신러닝이던 시각화던 원하는 작업을 진행할 수 있습니다.
start_time = time.time()
# Dask DataFrame을 실제로 계산하여 Pandas DataFrame으로 변환
computed_dask_df = dask_df.compute()
computed_dask_time = time.time() - start_time
print(f"Dask compute time: {computed_dask_time:.3f} seconds")
display(computed_dask_df)
Dask의 장점은?
눈치 좋으신 분들은 알아차리셨을 것 같습니다. Dask에선 결국 compute()를 통해 데이터프레임을 메모리에 올려야 하고, Compute 시간을 고려했을 때 Pandas 대비 읽는 시간이 크게 차이가 나지 않는 것을 볼 수 있습니다. (5억줄 200초 가량~)
그럼 Dask 왜 씀? 대용량 데이터프레임 처리하는데 속도가 똑같으면 그냥 Pandas Chunksize 조절해서 나눠 읽으면 되는거 아님? 난 메모리 용량도 충분해서 메모리 오류 안나는데? 라는 의문점이 떠오를 수 있습니다.
read_csv 이후 바로 compute를 해버리면 당연히 아무런 처리도 되지 않은 생짜배기 데이터프레임을 메모리에 올리므로, 메모리 절약이나 속도 향상 그 어떤 것도 기대하기 어렵습니다.
하지만 CPU-Intensive한 작업을 진행해야 할 때 DASK는 큰 힘을 발휘하는데요, 거두절미하고 예시코드와 결과물부터 보시죠.
# 전처리 List
# 1. Column A의 값이 5000 이상인 행 필터링
# 2. Column B의 값이 0.5 이상인 행 필터링
# 3. A와 B Column의 합을 새로운 Column 'X'에 추가
# 4. Column C의 값 별 Column X의 평균 계산
# 5. (DASK에서만 해당) Compute
# -----------------------------
# Pandas 처리 시간
# -----------------------------
start = time.time()
result_pandas = pandas_df[pandas_df['A'] >= 5000]
result_pandas = result_pandas[result_pandas['B'] >= 0.5]
result_pandas['X'] = result_pandas['A'] + result_pandas['B']
result_pandas = result_pandas.groupby('C')['X'].mean().reset_index()
pandas_time = time.time() - start
print(f"Pandas processing time: {pandas_time:.2f} sec")
# -----------------------------
# Dask 처리 시간
# -----------------------------
start = time.time()
# 1. Column A의 값이 5000 이상인 행 필터링
result_dask = dask_df[dask_df['A'] >= 5000]
# 2. Column B의 값이 0.5 이상인 행 필터링
result_dask = result_dask[result_dask['B'] >= 0.5]
# 3. A와 B Column의 합을 새로운 Column 'X'에 추가
result_dask['X'] = result_dask['A'] + result_dask['B']
# 4. Column C의 값 별 Column X의 평균 계산
result_dask = result_dask.groupby('C')['X'].mean().reset_index()
result_dask = result_dask.compute()
dask_time = time.time() - start
print(f"Dask processing time: {dask_time:.2f} sec")Pandas processing time: 180.31 sec
Dask processing time: 64.65 sec5억줄의 Dataframe을 간단히 처리하는데 Pandas는 180초 가량 소요되었으나, Dask에선 65초가 소요되었습니다.
Dask가 3배정도 빠르게 처리 결과물을 제공하는 것을 확인할 수 있었습니다.
어떻게 가능하지?
간단한 Big Data 연산 실험을 통해 Dask가 Pandas보다 훨씬 처리가 빠르다는 것을 확인했습니다.
Pandas는 각 연산 작업을 수행할 때마다 CPU 자원을 순차적으로 사용하지만 (Single-Thread), Dask는 Dataframe을 일정한 크기마다 Partition으로 나누고, 각 Partition마다 CPU Core를 할당 (Multi-Thread)하여 병렬 처리를 통해 여러 작업을 동시에 수행합니다.
또한 Lazy Execution 방식을 이용하므로, 연산 → 메모리 저장 → 연산 → 메모리 저장 → 반복과 같은 과정을 최소화하고, 최종 결과를 한 번에 계산하므로 추가적인 속도 향상을 이끌어낼 수 있습니다. (다만 이 부분은 경험상 큰 비율을 차지하지는 않더군요.)
결론
현업에서 AI 학습 시, 용량이 큰 Dataset에 대해 메모리 부족이나 시간 소요 등의 이슈를 흔히 겪을 수 있습니다.
Dask를 통해 대용량 데이터셋을 메모리 과부하나 속도 저하 없이 효율적으로 처리할 수 있는 것을 확인했습니다.
다만 주의할 점으로, 작은 데이터셋이나 간단한 연산에는 Dask의 오버헤드로 인해 오히려 속도가 떨어질 수 있습니다.
메모리 과부하가 우려되는 지점 (예를 들면 원본 데이터프레임을 필터링하거나 연산하기 전 단계) 에서 적절하게 사용하고, 시간이나 메모리 측면에서 부담되지 않는 연산이 있는 경우엔 compute 후 Pandas Dataframe으로 나머지 연산을 진행하는 것을 권장합니다.
'Knowledge > 개발' 카테고리의 다른 글
| [Github Pages] 블로그 유목민들을 위한 Full-Customizable Blog 추천 (0) | 2026.01.31 |
|---|---|
| [PyQt6] 파이썬으로 GUI를 구축할 수 있다? PyQt6 Library (0) | 2026.01.10 |
| [파이썬] 판다스 (Pandas), Multi-Index (멀티인덱스) 처리하는 방법 (0) | 2025.08.20 |



